Gemini API File Searchがマルチモーダル対応。画像・PDFを根拠付きで探せるRAG基盤とは?
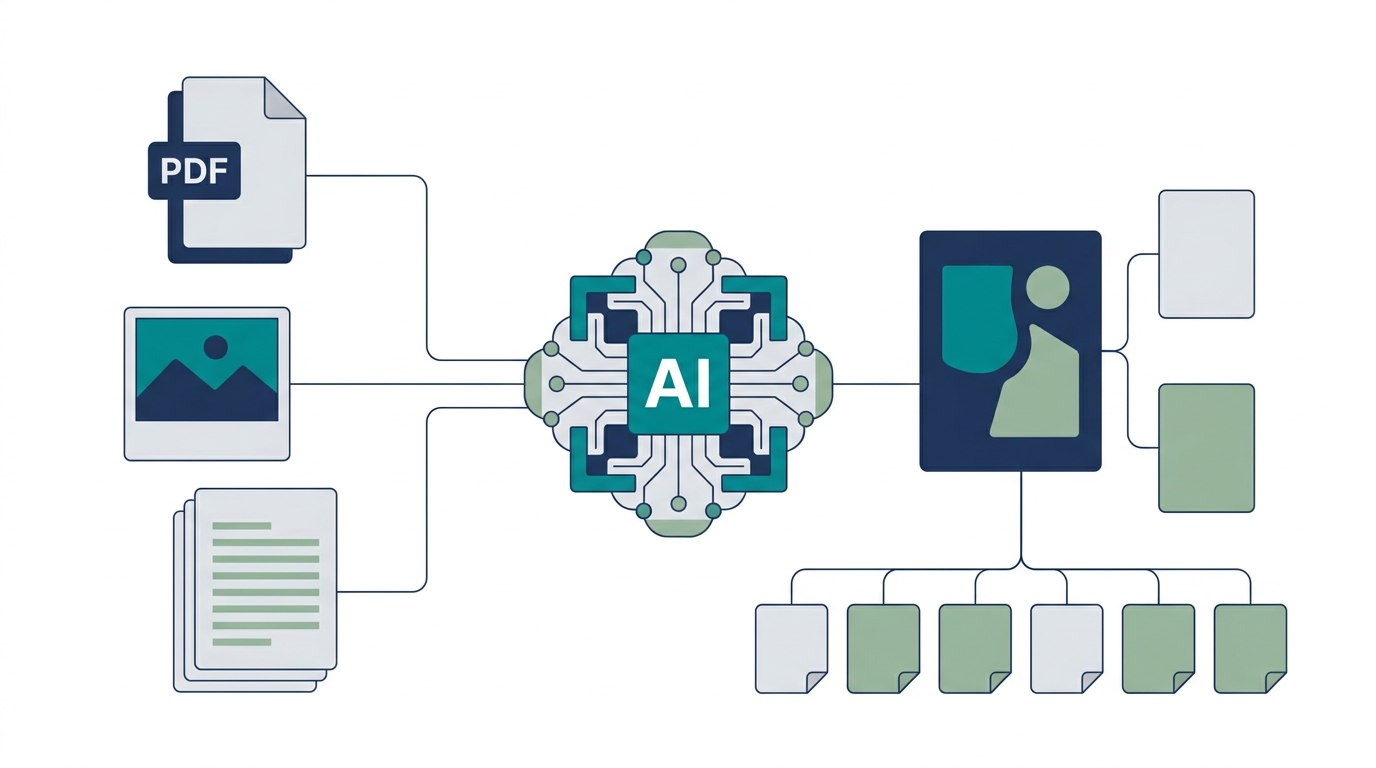
Google for Developersが、Gemini APIの File Searchの拡張 を発表しました。ひと言でいえば、Gemini APIだけで、画像やPDFを含むファイル群から必要な情報を探し、根拠を示しながら回答するRAGを作りやすくなった、というアップデートです。
今回のポイントは、File Searchがテキストだけでなく画像も扱えるマルチモーダルRAGに対応したこと、ファイルにカスタムメタデータを付けて検索範囲を絞れること、回答時にページ単位の引用を返せるようになったことです。営業資料、提案書、マニュアル、議事録、画像入りPDFを使うAIエージェントにとって、検索基盤を自前で作る負担を減らすアップデートといえます。
本記事のポイント
- Gemini API File Searchが、画像とテキストをまとめて扱うマルチモーダルRAGに対応しました。
- カスタムメタデータにより、部署、ステータス、資料種別などで検索対象を絞り込めます。
- ページ単位の引用により、AIの回答がどの資料のどのページに基づくのかを確認しやすくなります。
この記事で扱うテーマ
関連キーワード
- Gemini API File Search
- Gemini File Search
- Gemini API RAG
- マルチモーダルRAG
- Gemini API 画像検索
- Gemini API PDF検索
- RAG ページ引用
- Gemini Embedding 2
- AIエージェント ファイル検索
このページで答える質問
- Gemini API File Searchとは何ですか?
- Gemini API File Searchのマルチモーダル対応とは何ですか?
- マルチモーダルRAGとは何ですか?
- ページ単位の引用はなぜ重要ですか?
- 営業現場でGemini API File Searchはどう使えますか?
Gemini API File Searchとは何か
File Searchは、Gemini APIで使える検索・参照用の仕組みです。開発者はファイルを登録しておき、Geminiに質問したときに、関連するファイルの中身を探させて回答に使えます。一般的にはRAG、つまりRetrieval-Augmented Generationと呼ばれる構成に近いものです。
RAGは、AIモデルが学習済みの知識だけで答えるのではなく、手元のドキュメントや社内資料を検索し、その内容を根拠に回答する方式です。たとえば、営業提案書、製品マニュアル、FAQ、契約書、議事録、ナレッジベースを検索対象にして、「この顧客に近い事例は?」「この機能の制約は?」「この資料のどこに書いてある?」と聞けるようにします。
従来、このような仕組みを作るには、ファイルの取り込み、テキスト抽出、ベクトル化、ベクトルデータベース、検索、ランキング、引用、権限管理などを自前で組み合わせる必要がありました。File Searchは、そのうち検索・参照まわりのかなり面倒な部分をGemini API側に寄せるための機能です。
今回のアップデートで何が変わったのか
今回の発表で重要なのは、File Searchがより実務のファイルに近づいたことです。企業の資料は、きれいなテキストだけでできているわけではありません。PDFの中に図、表、スクリーンショット、写真、スライド画像が入り、ファイル名だけでは中身が分からないことも多くあります。
Googleは今回、File SearchがGemini Embedding 2を使い、画像とテキストを一緒に処理できると説明しています。つまり、画像をただ添付ファイルとして持つのではなく、画像の内容も検索対象として扱いやすくなる方向です。
| アップデート | 何ができるようになるか | 実務で効く場面 |
|---|---|---|
| 画像とテキストのネイティブ処理 | 画像入りPDFやビジュアル資料を、テキストだけでなく見た目の文脈も含めて検索しやすくなる。 | 提案書、製品カタログ、マニュアル、クリエイティブ資産の検索。 |
| カスタムメタデータ | department、status、documentTypeのようなラベルで検索対象を絞れる。 | 法務だけ、最新版だけ、営業資料だけ、といった検索範囲の制御。 |
| ページ単位の引用 | 回答の根拠が、どのファイルのどのページにあるかを示しやすくなる。 | 社内確認、顧客向け回答、監査、ファクトチェック。 |
なぜ「マルチモーダルRAG」が重要なのか
これまでのRAGは、テキスト文書を前提に語られることが多くありました。しかし、実際の業務データはマルチモーダルです。営業資料にはグラフや構成図があります。マニュアルにはスクリーンショットがあります。デザイン資料には画像があります。ホワイトペーパーやPDFには、本文と図表が混在しています。
テキストだけを抽出して検索すると、図の意味やレイアウト上の関係が落ちることがあります。たとえば「この資料の中で、青い画面に表示されている承認フローの例を探して」と聞きたい場合、ファイル名や本文キーワードだけでは十分に探せないことがあります。
マルチモーダルRAGは、この問題を少しずつ解きます。ユーザーが自然文で「こういう見た目」「この雰囲気」「この図に近い資料」と聞いたときに、画像やビジュアル要素も含めて検索できるようになるからです。Googleの発表でも、クリエイティブエージェンシーが大量のビジュアル資産から、特定の感情トーンや視覚スタイルに合う画像を探す例が挙げられています。
カスタムメタデータは検索精度と運用管理に効く
もう1つ重要なのが、カスタムメタデータです。大量のファイルをAIに読ませるだけでは、検索対象が広すぎてノイズが増えます。そこで、ファイルに部署、公開状態、版数、顧客種別、資料種別などのラベルを付けておき、質問時に検索対象を絞ります。
たとえば、同じ「契約条件」について聞く場合でも、営業資料、法務レビュー済み文書、古いドラフト、顧客向け説明資料が混ざっていると危険です。カスタムメタデータで status: final や department: legal のように絞れると、回答の根拠に使う資料を制御しやすくなります。
これは、AIエージェントを実務に入れるうえでかなり重要です。AIの賢さだけでなく、「どの資料を見てよいか」「最新版だけを見ているか」「顧客に見せてよい情報か」を制御できないと、現場では使いにくいからです。
ページ単位の引用は、AI回答の信頼性を上げる
AIが社内資料を読んで回答してくれても、「それはどこに書いてあるのか」が分からなければ、最終確認は難しくなります。特に、契約、仕様、料金、セキュリティ、顧客回答のような領域では、根拠確認が必須です。
今回のFile Searchでは、インデックスされた情報にページ番号を結びつけ、回答の根拠としてページ単位の引用を出せるようになったと説明されています。これにより、ユーザーはAIの答えをそのまま信じるのではなく、該当ページに戻って確認できます。
これは「AIエージェントを業務で使う」ための前提に近い機能です。回答が速いだけでは不十分で、検証できること、社内で説明できること、必要なら人間が元資料を確認できることが重要になります。
営業・マーケティング領域ではどう使えるか
ファネルAiの文脈で見ると、このアップデートは営業・マーケティング現場のAIエージェントに相性がよいです。営業活動では、Gmail、カレンダー、Drive、Meet、提案書、議事録、商談メモ、過去の提案資料が分散しています。これらを横断して、根拠付きで探せるようになると、商談準備や顧客対応の質が上がります。
たとえば、以下のような使い方が考えられます。
- 過去の提案書から、今回の顧客に近い業界・課題の事例を探す。
- 画像入りの製品資料やスライドから、特定の機能説明図を探す。
- 商談議事録と提案資料を横断して、次回提案で触れるべき論点を整理する。
- マニュアルPDFの該当ページを引用しながら、顧客向け回答の下書きを作る。
- 最新版の営業資料だけを対象にして、古い情報を回答に混ぜないようにする。
特に、Google Drive上の顧客データ活用 や Google Workspaceを使った営業管理 と組み合わせると、単なるファイル検索ではなく、営業活動の文脈を持ったAIエージェントに近づきます。
注意点:これだけで全てのRAG課題が消えるわけではない
一方で、File Searchが強化されたからといって、RAGの設計が不要になるわけではありません。実務では、どのファイルを入れるか、誰が見てよいか、古い資料をどう扱うか、顧客ごとのアクセス制御をどうするか、回答をどこまで自動化するかを決める必要があります。
また、ページ単位の引用があっても、回答内容の最終責任は業務側にあります。法務、料金、契約、セキュリティ、個人情報を含む回答では、人間の確認フローを残すべきです。AIエージェントに任せる範囲と、人間が承認する範囲を分けることが重要です。
導入時に確認したいチェックリスト
- 検索対象にするファイルの範囲を決める。
- 最新版、ドラフト、社外共有可否などのメタデータ設計を決める。
- 引用を必須にする回答領域を決める。
- 営業、CS、法務、情シスなど部門ごとのアクセス範囲を整理する。
- AI回答をそのまま使う場面と、人間承認を挟む場面を分ける。
- Google DriveやCRM/SFA上のデータとどう接続するかを設計する。
まとめ
Gemini API File Searchのマルチモーダル対応は、RAGを「テキスト検索の延長」から、画像やPDFを含む実務資料検索へ近づけるアップデートです。特に、画像とテキストのネイティブ処理、カスタムメタデータ、ページ単位の引用は、企業利用で重要な3点です。
営業資料、提案書、マニュアル、議事録、画像入りPDFを扱うAIエージェントを作る場合、自前で検索基盤を組み上げる前に、Gemini API File Searchでどこまで実現できるかを検証する価値があります。重要なのは、AIに何でも読ませることではなく、正しい資料を、正しい範囲で、根拠付きで使わせることです。
よくある質問
Gemini API File Searchとは何ですか?
Gemini APIで、登録したファイルを検索し、回答の根拠として使うための機能です。RAGを作る際の検索・参照部分をGemini API側で扱いやすくするものです。
今回のアップデートで何が新しくなりましたか?
画像とテキストをまとめて扱うマルチモーダル処理、カスタムメタデータによる絞り込み、ページ単位の引用が主な追加点です。
マルチモーダルRAGとは何ですか?
テキストだけでなく、画像、図表、スクリーンショット、PDF内のビジュアル要素も含めて検索・回答に使うRAGです。画像入り資料が多い業務で特に有効です。
ページ単位の引用はなぜ重要ですか?
AIの回答が、どの資料のどのページに基づいているかを確認できるためです。社内確認、顧客回答、監査、ファクトチェックで信頼性を高めます。
営業現場ではどう使えますか?
過去提案書の検索、顧客別の議事録整理、製品資料の該当ページ確認、FAQ回答の下書き、営業マニュアル検索などに使えます。Google DriveやCRM/SFAと組み合わせると、商談準備や顧客対応のAIエージェント化に近づきます。
参考情報
- Google Blog: Gemini API File Search is now multimodal: build efficient, verifiable RAG
- Google for Developersの告知ポスト
