AI検索時代の 検索意図グループ 設計とは?関連記事群の役割分担を固定する考え方
AI 検索時代の 検索意図グループ 設計は、細かい実装論に見えて、実は AI 検索時代のページ品質を左右する基礎部分です。ここが弱いと、どれだけ内容が良くても要約や比較の材料として使われにくくなります。
結論から言うと、検索意図グループ 設計は、似た記事を減らすためではなく、関連記事群の役割を固定して理解と比較の流れを作るための設計です。構造だけを先に作るのではなく、本文・見出し・比較軸・FAQ・内部リンクの整合まで同時に揃えることが重要です。
本記事のポイント
- 検索意図グループ 設計は、関連記事群に「定義記事/詳細記事/判断材料記事/接続記事」の4つの役割を固定する作業で、新規作成より既存記事の役割明確化を優先する方が短期間で効果が出ます。
- 各記事に「ここでは扱わない問い」を1行で決めておくと、似た記事同士が順位を奪い合うのを防ぎ、AI 引用面での文脈混乱も同時に避けられます。
- 効果は CTR ではなく「AI 引用面での表示」「比較検討での接触」「商談前行動」の3層で測ると、関連記事群全体の貢献を判断できます。
この記事で扱うテーマ
関連キーワード
- 検索意図グループ 設計
- AI検索 テーマ群 設計
- LLMO 検索意図グループ
- 主要解説記事 個別解説記事 違い
- AI検索 カニバリ防止
- 実例 記事 とは
- 記事 役割 固定
- 既存記事 改稿 優先順
このページで答える質問
- 検索意図グループ 設計とは何で、SEO/AEO/LLMO/GEO とどう違うのか?
- 定義記事・詳細記事・判断材料記事・接続記事の4役割はどう分けるのか?
- 新規作成と既存記事の改稿、どちらを優先すべきか?
- 検索意図グループ 設計の効果は CTR に依存せずどう測るのか?
SEO・AEO・LLMO・GEO と 検索意図グループ の位置付け
検索意図グループ 設計は、SEO・AEO・LLMO・GEO の4概念の上に乗る「URL レイヤーの設計」です。各概念がページ単位の最適化を扱うのに対し、検索意図グループ は関連記事群全体での役割分担を扱います。
| 概念 | 焦点 | 主な施策 | ページ上で見る場所 |
|---|---|---|---|
| SEO | 検索結果で見つけてもらう | 検索意図、クロール、内部リンク、title | title・h1・内部リンク・canonical |
| AEO | 質問に対する答えを短く正確に返す | answer target 設計、見出し直下の結論、FAQ | 冒頭回答・H2 直下・FAQ・比較表 |
| GEO | 生成回答で引用元・比較材料として使われる | 一次情報、比較軸、制約条件、向くケース | 比較表・導入条件・向き不向き・独自整理 |
| LLMO | AI 回答面で意味を崩さず伝える全体設計 | 本文構造、責任主体、関連導線、更新鮮度 | 本文全体・監修情報・関連記事・構造化データ |
4概念のいずれかだけを最適化しても、関連記事群の中での役割分担が曖昧だと AI 検索面で「どの URL がそのテーマの中心か」を判断されにくくなります。検索意図グループ 設計は、これらの上位レイヤーで関連記事群全体を整えます。
AI 検索時代の 検索意図グループ 設計が重要になる理由
AI 検索では、同じテーマで似た記事が増えると、どのページがカテゴリ定義で、どのページが比較で、どのページが導入判断なのかが曖昧になります。これは検索順位の問題だけでなく、AI が文脈を束ねにくくなる問題でもあります。
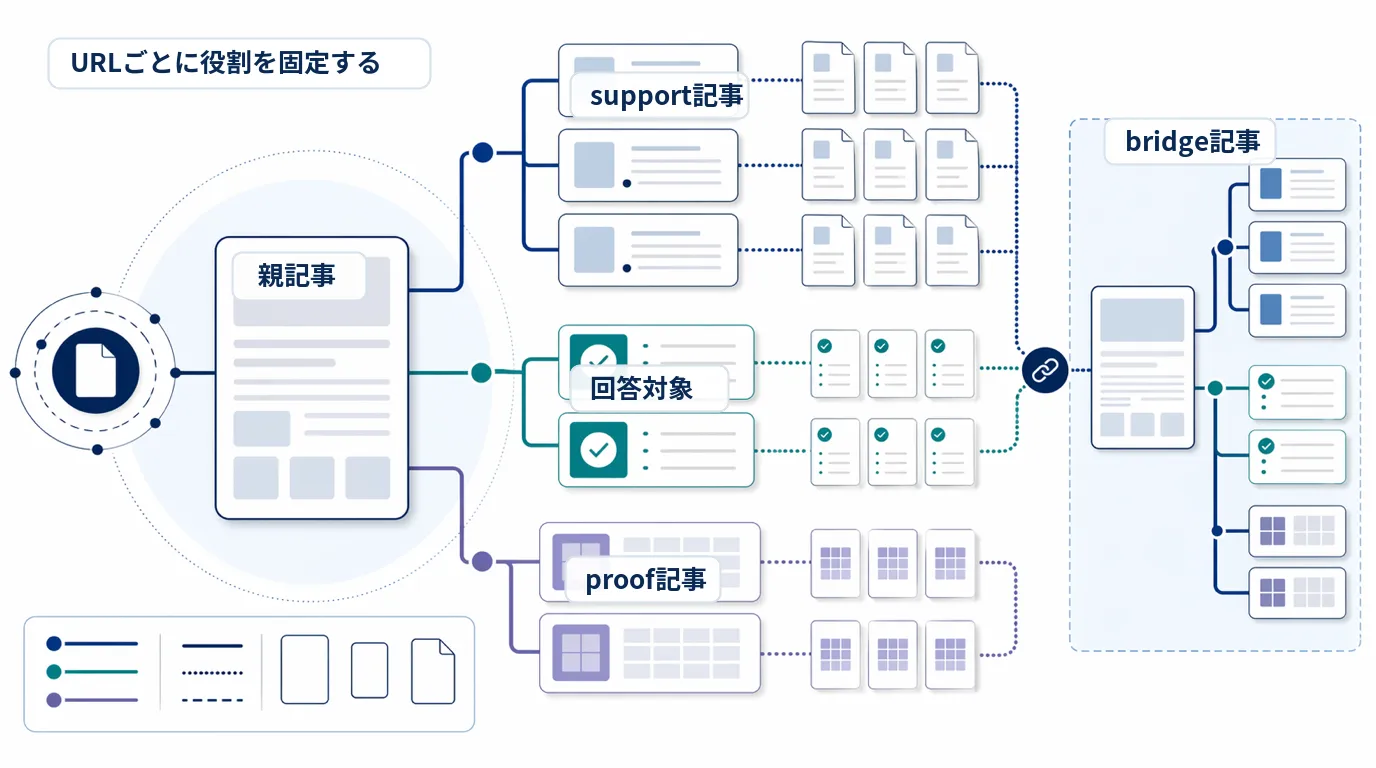
BtoB では「概念を知りたい段階」に答える定義記事、個別の質問に答える詳細記事、比較や導入判断の材料を提供する判断材料記事の3種類が必要です。内部リンク設計 と合わせて考えると役割が固定しやすくなります。
たとえば「営業 AI とは何か」を答える定義記事と、「営業 AI と MA の違い」を答える詳細記事と、「営業 AI の導入費用と体制要件」を答える判断材料記事が別々に存在することで、AI が回答を生成するときに引用元となるページが目的ごとに分かれます。逆に定義記事が3つある状態では、どれがそのテーマの中心かが判断できず、引用候補から外れるリスクが高まります。BtoB の意思決定は複数の関与者が異なるフェーズで情報を調べるため、役割の重複が特に損失を生みやすい構造です。
検索意図グループ 設計は、記事を増やす前に「誰が何を答えるか」を決める仕事です。
4つの役割の設計原則
| 役割 | 主に答える問い | 例 |
|---|---|---|
| 定義記事 | これは何か、全体像は何か | llmo-toha、ai-search-optimization |
| 詳細記事 | 個別の論点はどう考えるか | ai-search-faq-design、ai-search-answer-targets |
| 判断材料記事 | 比較や導入判断にどう効くか | b2b-llmo-kpi、sales-ai-llmo |
| 接続記事 | 隣接テーマとどうつながるか | marketing-ai-llmo、sales-ai-llmo |
検索意図グループ 設計の作り方
- 対象テーマで「概念を知りたい段階の問い」と「比較・導入を判断する段階の問い」を洗い出す。
- 定義記事・詳細記事・判断材料記事の役割を決め、どの URL がどの問いを担当するかを固定する。
- 関連記事と内部リンクで、定義記事から詳細記事と判断材料記事へ流す。
- 既存記事との重複を見て、新規作成か改稿かを先に決める。
実務での進め方として、まず対象テーマの記事を全量スプレッドシートに一覧化し、title と meta description を並べてみると重複が見えやすくなります。同じ問いに複数の記事が答えている場合は、どちらを正規記事として残すかを先に決め、もう一方は内容を別の役割へ転換するか統合するかを判断します。新規作成を急ぐより、既存記事の役割を明確化する方が AI 検索では短期間で効果が出やすい傾向があります。特に詳細記事と判断材料記事が混在している場合は、比較軸と導入判断の情報をどちらに集約するかを決めるだけで関連記事群全体の意味が整いやすくなります。
検索意図グループ 設計で見直したい確認ポイント
- 定義記事がカテゴリ定義を担っているか。
- 詳細記事が個別の論点に絞れているか。
- 判断材料記事が比較や導入判断を受けているか。
- 似た title が複数あり、役割が競合していないか。
これらの確認を実際に行う際は、全記事の title と meta description を一覧化した棚卸しシートを作り、各記事に「これは定義・比較・導入判断のどれか」を一言で書く作業から始めると役割の重複が視覚的に分かりやすくなります。特に判断材料記事が存在しないテーマは、問い合わせ前の最終判断材料が欠けている状態であるため、優先的に補強の対象になります。BtoB の営業フローと照らし合わせて「この記事は商談前のどの段階の疑問に答えるか」を記録しておくと、検索意図グループ の設計がビジネス目標と直結した形で管理できます。
検索意図グループ 設計で起こりやすい失敗
- 定義記事がないまま詳細記事だけ増える。
- 比較記事と詳細記事で同じ問いを扱い、役割が重複する。
- 新規作成を優先し過ぎて、既存記事の改稿で済むテーマまで増やしてしまう。
特に「定義記事がない状態」は、そのテーマ全体の信頼性を下げる要因になります。たとえば「AI CRM 比較」「AI CRM 費用」「AI CRM 導入事例」の記事が揃っていても、「AI CRM とは何か」を定義する記事がなければ、AI が比較や費用の判断材料を正しい文脈で引用しにくくなります。BtoB では検討期間が長く、関与者が異なるタイミングで同じテーマを調べるため、定義から比較・導入まで一本筋として辿れる 検索意図グループ の存在が、最終的な問い合わせ率にも影響します。
テーマごとに「あえて受けない問い」も決める
検索意図グループ 設計では、答える問いだけでなく、あえて受けない問いも決める必要があります。定義記事が導入費用まで深く答え始めると判断材料記事と競合し、詳細記事が広い定義を語り始めると定義記事と競合します。
そのため、各記事に「このページでは扱わないこと」を1行で決めておくと運用がぶれにくくなります。新規記事を作る前に、既存記事の title と役割と除外範囲を並べて確認する方が、似た記事同士の順位の奪い合いを防ぎやすくなります。
| 記事の役割 | 受ける問い | 受けない問い |
|---|---|---|
| 定義記事 | これは何か、全体像は何か | 個別製品比較や費用詳細 |
| 詳細記事 | 個別の論点はどう考えるか | 広い定義や全体像 |
| 判断材料記事 | 比較や導入判断にどう効くか | 概念定義だけの説明 |
測定軸|CTR に依存しない3層
検索意図グループ 設計の効果は、単一の数値では測りにくくなります。CTR や順位だけでは「関連記事群全体での意味の整合」が見えず、設計を変えた効果を捕まえられません。次の3層を組み合わせると、関連記事群全体の貢献を判断しやすくなります。
| 測定軸 | 何を見るか | 改善シグナルの例 |
|---|---|---|
| AI 引用面での表示 | ChatGPT Search・Perplexity・AI Overview で、定義記事・詳細記事・判断材料記事のどれが引用されているかを月次で観測 | 役割に応じた URL が正しい問いで引用される |
| 比較検討での接触 | GA4 で定義記事 → 詳細記事 → 判断材料記事へのフロー、関連記事ブロックからの遷移率 | 定義記事から比較記事への遷移率向上、滞在時間 +30% |
| 商談前行動 | 問い合わせ前7日の接触ページ path、判断材料記事への到達率 | CTA 手前の判断材料記事到達増、問い合わせ率向上 |
この3層は ゼロクリック時代の BtoB SEO でさらに整理しています。検索意図グループ 単独で完結させず、関連記事群5本を横串で運用するのが現実的です。
よくある質問
定義記事と詳細記事の違いは何ですか?
定義記事は全体像・定義・カテゴリ分類を扱い、詳細記事は個別の質問・実装論を扱います。同じテーマで定義記事が複数あると、そのテーマの中心がどこか分散してしまうため、1テーマ1定義記事が原則です。
判断材料記事とは何ですか?
比較・KPI・導入判断・事例のように、商談前の意思決定材料として再利用される記事です。「印刷して稟議資料になるか」を目安にすると、詳細記事と判断材料記事の境界が判断しやすくなります。
似た記事同士の順位の奪い合いはどう防げますか?
「受けない問い」を各記事に1行で記録し、新規作成前に既存テーマ群の中に同じ問いを扱う記事がないかを必ず確認します。役割が重複しているなら新規作成より統合・改稿を優先するのが鉄則です。
BtoB で関連記事群の役割設計が特に重要なのはなぜですか?
比較検討の関与者(マーケ/IT/経営)が多く、問いの深さが段階的に変わるためです。役割分担がないと、関与者ごとに調べる問いが分散し、テーマ全体で「どこが中心か」が伝わりにくくなります。
既存記事の改稿と新規作成、どちらを優先すべきですか?
既存記事の改稿が原則です。新規作成は最終手段として捉え、まずテーマ内の既存記事を一覧化し、役割の重複・欠落を確認します。「既存 A → 詳細記事化、既存 B → 判断材料記事化、空白の役割だけ新規作成」の順で進めると、評価の集中とリソース効率の両立が可能です。
関連記事群の中で記事をマージする判断基準は?
同じ問いに対する答えが2記事以上で重複し、URL として残す価値が片方しかない場合に統合します。被リンク数・GSC 実績・記事年齢を見て、強い方を残し弱い方を 301 リダイレクトで集約するのが基本です。
canonical 設計はどう関係しますか?
役割が重複した記事を残す場合、片方を canonical で指すか、`noindex` にすることで AI 検索面での評価分散を防げます。ただし長期的には統合や役割転換が望ましく、canonical 依存は短期対策に留めます。
テーマ全体を改稿する優先順位の決め方は?
(1) 定義記事の有無、(2) 判断材料記事の有無、(3) 詳細記事の役割重複、の順で確認します。定義記事がないテーマは中心が不明、判断材料記事がないテーマは商談前行動が取れない、詳細記事の重複は中位の課題です。詳細は 内部リンク設計 をあわせて参照してください。
