音声AIエージェントとは?Gemini Live API × Google ADKで電話対応を自動化する構成と実装ステップ
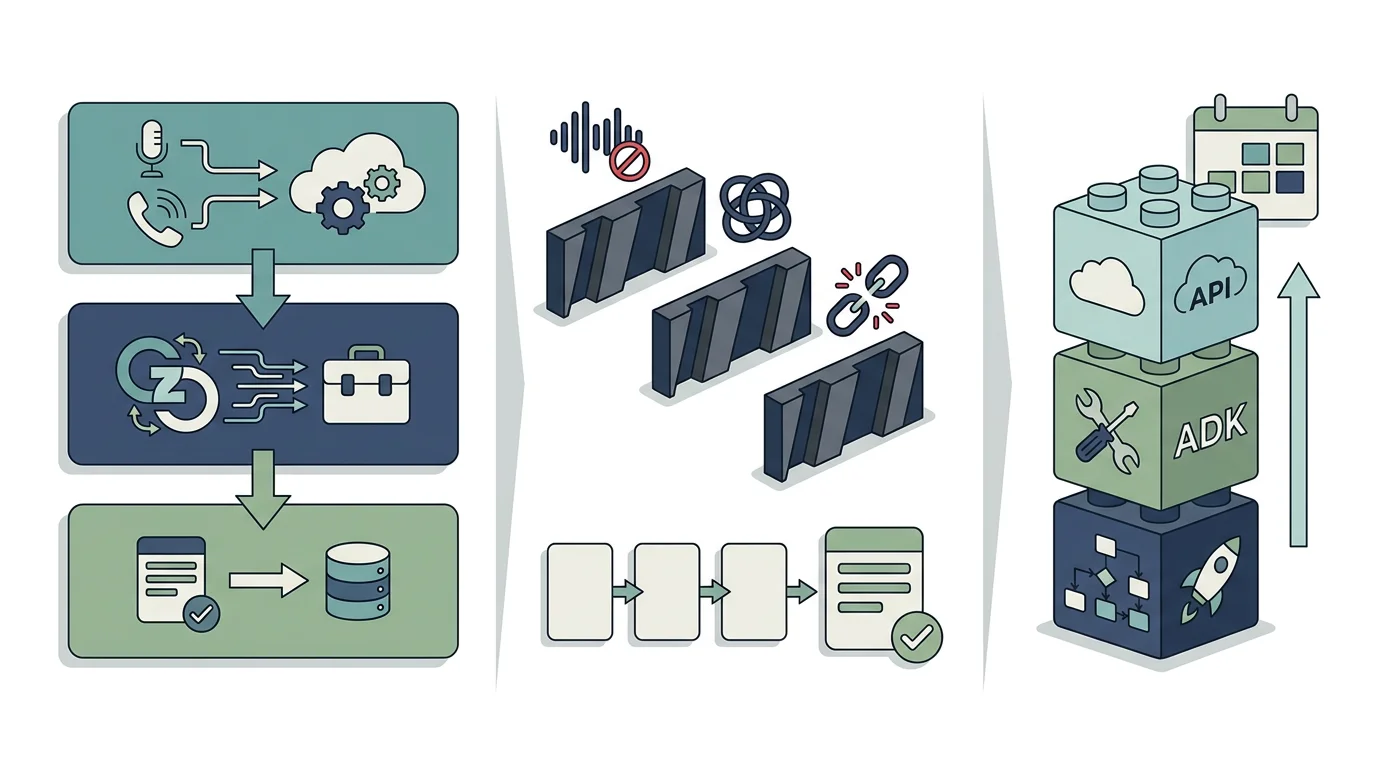
電話の一次受けや申込受付など、人が会話で情報を取り切ってシステムに登録する業務は、長く「IVR → オペレータ → CRM入力」の3段階で組まれてきました。海外のデモ動画では、この3段階を音声AIエージェント1体で置き換える構成が動き始めています。リアルタイムで顧客の声を認識し、必要項目を会話で取り切り、抽出した情報をフォームへ自動入力してルーティングまで完結させる、というものです。
中身は、GoogleのGemini Live API(双方向ストリーミング音声、低レイテンシ、割り込み可)でI/Oを捌き、Google ADK(Agent Development Kit)でヒアリング→抽出→ルーティングのツール連鎖を組み、CRM/フォームのAPIに書き込む3層構成です。技術的には公開APIだけで作れて難易度は中ですが、業務に乗せるには日本語の固有名詞精度・会話設計・既存システム連携の3つの壁を越える必要があります。
結論を先に言うと、保険受付のような責任の重い領域からいきなり本番化を狙うより、営業の一次受け(資料請求の電話対応+ヒアリング自動化)のように失敗時にオペレータへ引き継げる業務でPoCを2週間で組む方が、音声品質と業務リスクの両面で着地しやすい筋になります。本記事ではデモの構成を解体しつつ、自社で同じものを組むときの判断軸を整理します。
本記事のポイント
- 音声AIエージェントは、IVR→オペレータ→CRM入力の3工程を1体に集約する構成。Gemini Live APIで音声、Google ADKでツール連鎖、CRM APIで書き込む3層が標準形です。
- 公開APIだけで作れて技術的難易度は中ですが、日本語の固有名詞精度・会話設計・既存システム連携の3つの壁が本番工数の半分以上を占めます。
- 保険受付より営業の一次受け(資料請求の電話対応+ヒアリング自動化)から始める方が、失敗時にオペレータへ引き継げて2週間でPoCを組みやすい筋になります。
音声AIエージェントとは何か:IVR→オペレータ→CRM入力を1体で置き換える
音声AIエージェントは、人が電話やマイク越しに話しかけると、リアルタイムで音声を認識して意味を理解し、不足している項目を会話で取り切り、抽出した情報を構造化データに整形してフォームやCRMへ自動入力し、ルールに従って担当者へルーティングする、までを1体のエージェントで完結させる構成を指します。海外で公開されている保険受付のデモは、まさにこの構成を全部1体に寄せにいっています。
従来のコールセンター業務は、おおまかに「IVR(自動音声応答)で要件を仕分け → オペレータが会話で詳細をヒアリング → 通話後にCRMやフォームへ手で入力」という3段階で組まれてきました。それぞれが別の技術スタック・別の担当・別のツールで動いており、つなぎ目で待ち時間とミスが生まれるのが構造的な問題でした。
音声AIエージェントが面白いのは、この3段階を「会話しながら、その場で構造化データを作っていく」ことで論理的に1段に潰せる点です。応対品質の標準化、24時間対応、入力ミスゼロ、CRMとのリアルタイム同期、といった効果がまとめて出てきます。
| 従来構成 | 音声AIエージェント構成 | 変わるポイント |
|---|---|---|
| IVRで要件を仕分け | 会話の意味理解で自動分岐 | 「1番を押してください」が消え、自然言語のまま分岐できる |
| オペレータが項目をヒアリング | エージェントが必要項目を聞き取る | 応対品質の標準化、24時間対応、平日夜間・休日の取りこぼし防止 |
| 通話後にCRMへ手入力 | 会話中に構造化データを作って自動投入 | 入力ミスゼロ、登録漏れゼロ、後工程への即時引き渡し |
| ルーティングは台帳・カンを使う | 抽出済み属性とルールで自動ルーティング | 担当アサイン精度が上がり、たらい回しが減る |
音声AIエージェントの本質は「音声で動くチャットボット」ではなく、会話しながら構造化データを作る業務処理エンジンです。
同じ流れは 営業電話AI(オートコール) でアウトバウンド側がすでに実用化されつつあり、これがインバウンド(受電)側にも降りてきている、と捉えるのが分かりやすい構図です。
3層アーキテクチャの解体:音声I/O × オーケストレーション × 出力ツール
デモ動画のような音声AIエージェントは、ほぼ間違いなく次の3層で構成されています。それぞれの層に何を載せるかが分かれば、PoCの設計図はかなり書けます。
第1層:音声I/O — Gemini Live API
顧客と話す部分を担う層です。Googleが提供する Gemini Live API は、双方向のストリーミング音声をネイティブに扱える仕組みで、人がしゃべっている最中にエージェントが割り込んで応答できる、応答までのレイテンシが短い(おおむね1秒以内に収まりやすい)、感情やトーンを含めて意味を理解しやすい、という特徴があります。
従来は「音声 → STT(音声→テキスト変換) → LLM → TTS(テキスト→音声合成)」と4つのコンポーネントを直列で繋ぐのが定石で、各段でレイテンシと精度が落ちていました。Live APIはこのパイプラインをLLMにネイティブ統合する方向に振った設計で、人と話している感覚に近い応答が出せる点が一番の差です。
第2層:オーケストレーション — Google ADK
会話の流れを設計し、必要な処理を呼び分ける層です。Googleが2025年4月にOSSとして公開した Agent Development Kit(ADK) は、複数のエージェントを階層的に組み合わせ、ツール呼び出しを連鎖させるためのフレームワークです。
保険受付デモの典型的な内部構成は、こんな分担になっているはずです。
| サブエージェント | 役割 | 使うツール例 |
|---|---|---|
| intake_agent | 受電直後に要件を聞き、適切なフローへ分岐 | 顧客マスタ参照、契約照会 |
| extraction_agent | 必要項目(氏名、事故日、状況など)を会話で取り切る | 項目チェック、必須/任意の分類 |
| routing_agent | 抽出結果から担当チーム・優先度を判定 | ルールエンジン、担当アサインAPI |
| recording_agent | 会話の要約と通話ログを保存 | 要約LLM、ログDB書き込み |
ADKの利点は、エージェントとツールが「Pythonの関数を FunctionTool としてラップするだけ」で組める点です。社内CRMのAPIをラップした関数を1つ書けば、それをエージェントが必要なタイミングで呼び出してくれます。エージェント間の権限分離やログ取得もフレームワーク側で支援されており、AIエージェントの権限設計と運用ランブックを実装する土台として整っています。
第3層:出力ツール — CRM/フォームAPI連携
抽出した情報を「業務システムに反映させる」最後の層です。Salesforce、kintone、HubSpot、独自CRMなどが対象になります。デモではこの層が一番きれいに見えますが、実務で本番に乗せるとここの作り込みが工数の半分以上を占めることが多いポイントです。
具体的には、CRMの登録項目に対する型変換、必須項目検証、重複検知、エラー時のフォールバック、業務ルールに沿った自動採番、担当者アサインのロジック、Slackや電話通知への引き継ぎ、といった要素が積み上がります。生成AIの精度より、この「最後の1歩」の地味な作り込みが本番品質を決めます。
業務に乗せるときに越えるべき3つの壁
「動くデモ」と「業務に乗る音声AIエージェント」の間には、大きく3つの壁があります。デモが派手なほど、この壁の存在が見えにくくなる点に注意してください。
壁1:日本語の固有名詞精度
音声認識の精度は、英語に比べて日本語の方が落ちやすい領域です。特に、地名、人名、薬剤名、契約番号、商品コードなど、業務ドメイン固有の固有名詞は、汎用モデルだけでは聞き取れないケースが頻発します。
対策は、Live APIへ渡すシステムプロンプトに語彙ヒント(よく出てくる地名・薬剤名・型番リスト)を含める、業務ドメインに特化したASR(OpenAI Whisperなど)と併用して書き起こしを照合する、確信度が低い項目は会話でリピート確認する、といった層を重ねることです。最初から完璧な認識を狙わず、聞き直す会話設計まで含めて品質を担保します。
壁2:会話設計(沈黙・言い直し・項目順)
LLMにフリーで喋らせると、業務会話は崩れます。重要な設計論点は次の3つです。
- 項目を1つずつ聞くか、まとめて聞くか:効率を優先するとまとめて聞きたくなりますが、相手が高齢だったり、内容が複雑だと項目落ちが増えます。一次受けは1つずつ、エキスパート層は要約後に確認、といった切り分けが必要です。
- 言い直しの取り扱い:「あ、間違えました、3月15日です」のような訂正を、過去の抽出値に上書き反映できるか。プロンプトと状態管理の両面で設計が要ります。
- 沈黙の打ち切り判定:相手が考え込んで黙っている時間を、どこから「次の問いかけ」に切り替えるか。短すぎると圧迫的、長すぎると無音状態が続きます。
これは生成AIの精度ではなく、UX設計の問題です。いきなり全自動でなく、エージェント運用のガバナンスと同じ発想で、「異常系」を先に決めてから動かすのが定石です。
壁3:既存システム連携の作り込み
本番工数の半分以上を占めるのがこの層です。Salesforce、kintone、HubSpot、自社開発CRMなど、既存の業務システムへ書き込むには、それぞれのAPI仕様、認証方式、項目マッピング、エラー処理を作り込む必要があります。
特にレガシーな自社CRMはAPIが整備されていないケースもあり、その場合はAPIラッパーや中間DBを先に整備してからエージェントを乗せる、という順序が現実的です。「AIを入れる前に業務基盤を整える」という、AI導入では避けて通れない原則がここでも効いてきます。
最小構成PoCの設計:営業の一次受けから2週間で組む
音声AIエージェントを試すなら、保険受付のような責任の重い領域から始めるより、もっと業務リスクの低い領域から入るのが推奨です。具体的には、営業の一次受け(インバウンドの資料請求電話対応+ヒアリング自動化) が筋の良い起点になります。理由は3つあります。
| 選定理由 | 具体内容 | PoCに与える効果 |
|---|---|---|
| ヒアリング項目が少ない | 会社名、担当者名、検討状況、希望、連絡可能時間など5〜7項目で済む | 音声品質の壁を低く保てる、初回成功率が高い |
| 失敗時のリカバリが容易 | うまくいかなければオペレータに引き継ぐ運用にできる | 業務リスクが小さく、本番事故が起きにくい |
| ドメインが明確 | 「ファネル」「営業」というテーマに直結し、自社プロダクトの差別化機能として刺さる | PoCのROIを社内に説明しやすい |
推奨スタック
| 層 | 採用候補 | 選定理由 |
|---|---|---|
| 音声I/O | Gemini Live API | 双方向音声をネイティブ処理、低レイテンシ、日本語対応 |
| オーケストレーション | Google ADK | OSSで無料、エージェント連鎖とFunctionTool登録が簡潔 |
| CRM書き込み | HubSpot API or kintone API | API整備済み、認証も成熟、初期PoCに向く |
| 電話受信 | Twilio または Google Voice | SIP接続が容易、課金体系が分かりやすい |
2週間PoCの作業ステップ
- 1週目前半(2〜3日):ヒアリング項目(5〜7項目)と会話フローの設計、システムプロンプト作成、ツール呼び出し関数の設計
- 1週目後半(2〜3日):ADKでエージェント連鎖を実装、Live APIでローカル音声テスト、CRM API書き込み関数の実装
- 2週目前半(2〜3日):Twilio経由で実電話と接続、社内テスト、固有名詞ヒントとリピート確認の追加
- 2週目後半(2〜3日):成功率と引き継ぎログを計測、運用設計(オペレータ引き継ぎ閾値、エラー通知、停止条件)を固める
ここまでが最小PoCで、本番運用までの距離はおおむね2〜3ヶ月見ておくのが現実的です。本番化のフェーズで一番重い作業は、運用ランブックの整備と権限・監査ログ設計になります。
動くデモは2週間、業務に乗る音声AIエージェントは2〜3ヶ月。スタックは公開APIで揃いますが、本番品質は会話設計と既存システム連携の作り込みで決まります。
よくある質問
音声AIエージェントは、既存のIVRやチャットボットと何が違うのですか?
IVRは「番号を押してください」式の選択肢分岐で、自然言語の意味理解はできません。チャットボットはテキスト前提で、電話の入電をそのままは扱えません。音声AIエージェントは、自然言語で話しかけられて意味を理解し、必要項目を会話で取り切り、抽出データを構造化して業務システムへ書き込むまで1体で完結する点が違います。
Gemini Live APIではなく、OpenAIのRealtime APIでも作れますか?
作れます。OpenAIのRealtime APIも双方向ストリーミング音声に対応しており、構成上の選択肢になります。違いは、ADKがGoogleエコシステム最適で組まれていること、Live APIの方が日本語の自然さで評判が良いケースが多いこと、料金体系が異なることなどです。社内が既にGoogle Cloudで動いているならGemini Live + ADK、それ以外なら両方をPoCで試す価値があります。
本番運用で月額コストはどのくらいかかりますか?
規模次第ですが、PoCレベル(月数百件)なら、Live API・ADK・CRM API・Twilioを合わせて月数万円〜十数万円が目安です。本番運用(月数千件〜万件)になると、音声処理のトークン課金が支配的になり、月数十万円〜百万円規模を見込むケースが出てきます。コスト試算は、平均通話時間と1日あたり処理件数を先に決めてから行うのが正確です。
日本語の固有名詞精度はどのくらい上がりますか?
汎用設定のままだと、地名・薬剤名・契約番号など業務固有語彙の認識精度は実用に届きにくいことが多いです。語彙ヒントの追加、Whisperなど別モデルとの併用、リピート確認の会話設計、を組み合わせることで実用ラインに近づきます。1回の認識で完璧を狙わず、「会話で訂正できる前提」で品質を組むのが現実解です。
