AIエージェントのコンテキストロットとは?長い会話で精度が崩れる原因と防ぎ方
AIエージェントを営業、サポート、社内自動化に入れると、最初の数ターンは自然に見えても、会話が長くなるほど話がかみ合わなくなることがあります。顧客がすでに答えたことを聞き直す、途中で意図を取り違える、関係ない知識を持ち込む、といった崩れ方です。
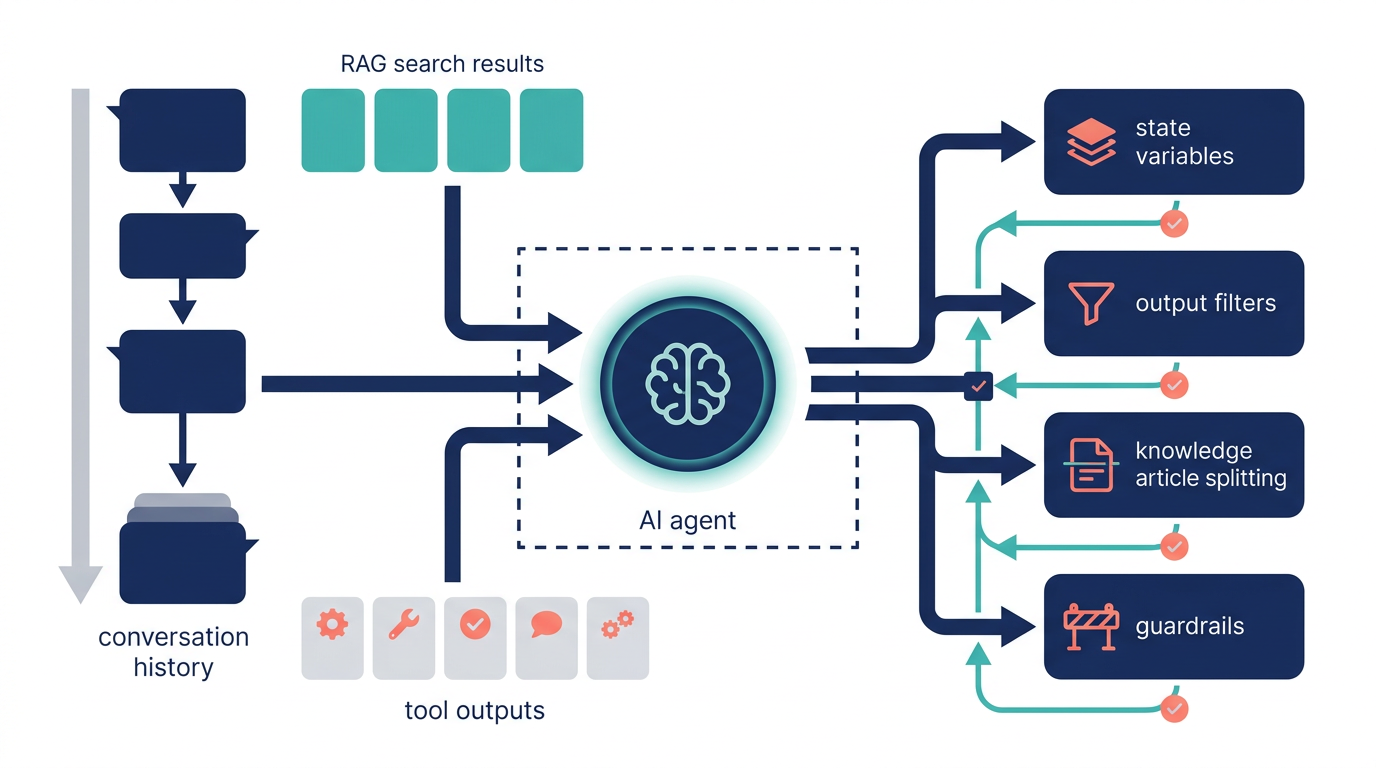
このとき原因を「モデルが弱い」「RAGが足りない」で片付けると、設計の論点を外します。実務で起きやすいのは、会話履歴、検索結果、ツール出力が同じ文脈枠を奪い合い、重要な前提が後ろへ押し出される コンテキストロット です。
AIエージェントのコンテキストロットとは、長い会話の中で履歴、RAG、ツール出力が増えすぎ、重要な前提や直近の意図変更がコンテキスト枠から落ちて精度が崩れる現象です。単なるモデル性能不足とは別問題で、知識記事の粒度、出力整形、状態保持、guardrail 設計を見直すと改善しやすくなります。
本記事のポイント
- コンテキストロットは、会話履歴、RAG検索結果、ツール出力が同じ文脈枠を奪い合い、長い会話ほど重要な前提が落ちる現象です。
- RAG不足、権限不足、単なるモデル精度不足とは別問題で、知識記事の分割、アクション出力の絞り込み、状態変数の設計で改善しやすくなります。
- PoCでは平均正答率だけでなく、5ターン超の解決率、聞き直し率、想定外 escalation 率を別で追うと、本番での崩れ方を見抜きやすくなります.
コンテキストロットとは何か
コンテキストロットとは、AIエージェントが会話を続けるほど、保持しておくべき重要な前提が薄れたり抜け落ちたりして、推論の質が落ちる現象です。会話履歴が長くなるだけでなく、検索したナレッジ、APIやCRMから返ったデータ、途中で発生したツール出力も同じコンテキスト枠に入るため、必要な情報が競合します。
その結果、エージェントは「今の顧客意図」を見失い、古い前提やノイズの多い情報をもとにもっともらしい返答を作ります。営業なら商談目的を取り違える、サポートなら既出の回答を繰り返す、社内自動化なら途中で上書きされた条件を忘れる、といった形で現れます。
| 現象 | 内部で起きていること | 現場で見える症状 |
|---|---|---|
| 履歴の押し出し | 初期の顧客条件や意図変更が文脈枠から落ちる | すでに答えた質問を聞き直す |
| 検索ノイズの流入 | 多話題のナレッジ断片が大量に混ざる | 関係ないFAQや規約を持ち込む |
| 出力肥大化 | APIレスポンスやCRM全項目がそのまま入る | 途中から返答が鈍くなる、要点がぼやける |
| 古い状態の残留 | ユーザーが意図を変えても以前の状態が残る | 取り下げた依頼に基づいて動こうとする |
重要なのは、これは「AIがバカになった」のではなく、有限の文脈枠に対して情報を入れすぎた設計の問題 だということです。だから改善の主戦場はモデル変更ではなく、何を残し、何を捨てるかの設計になります。
RAG不足や権限不足と何が違うのか
コンテキストロットは、似た失敗要因と混同されやすい論点です。特に `RAG が弱い`, `権限が足りない`, `モデル精度が低い` は別の問題なので、切り分けを誤ると対策もずれます。
| 論点 | 何が足りない / 起きているか | 典型症状 | 主な対策 |
|---|---|---|---|
| コンテキストロット | 重要前提が文脈枠から押し出される | 長会話で精度低下、聞き直し、意図の逆戻り | 記事分割、出力整形、状態変数、guardrails |
| RAG不足 | 必要な知識を拾えていない | 制度や規約を知らない、根拠が薄い | 検索対象の整備、chunk設計、記事追加 |
| 権限不足 | 必要データや操作権限にアクセスできない | 顧客情報を読めない、更新できない | 権限設計 の見直し |
| モデル精度不足 | 推論能力や指示追従が用途に合っていない | 短会話でも誤答が多い | モデル変更、prompt改善、評価設計 |
実務では、短いデモは成功するのに本番でだけ崩れるなら、まずコンテキストロットを疑うべきです。RAG不足なら最初から必要知識を引けませんし、権限不足なら取得できないデータの範囲が一貫して再現されます。長いやり取りでだけ崩れるのは、情報量の積み上がりによる設計問題であることが多くなります。
営業・サポート・社内自動化でどう現れるか
コンテキストロットは抽象概念に見えますが、現場ではかなり具体的に現れます。業務ごとに崩れ方が違うので、症状を業務文脈で見た方が判断しやすくなります。
営業AIエージェントの場合
顧客が「まずは情報収集」と言っていたのに、数ターン後にエージェントが商談化前提の提案へ飛ぶ、複数の決裁者情報を取り違える、すでに共有済みの資料を再送候補に入れる、といった形で表れます。特に CRM 出力をそのまま流し込むと、案件履歴のノイズで重要な直近意図が埋もれやすくなります。
サポートAIエージェントの場合
返金、停止、プラン変更のように途中で顧客意図が変わるケースで崩れやすくなります。最初は「解約したい」と言っていた顧客が、途中で「一時停止に変えたい」と修正したのに、後半でエージェントが解約フローに戻るのは典型例です。
社内自動化エージェントの場合
問い合わせ分類、台帳更新、承認依頼のようなフローで、途中で上書きされた条件を忘れます。たとえば「A部門案件だけSlack通知」「金額が50万円超なら人間承認」のような条件が、複数ツール出力の間で薄れて誤処理につながります。ここは SoA や AIエージェント ガバナンス とつないで考える必要があります。
防止策5つ
Salesforce の context rot 記事が整理している論点は、特定製品を超えてそのまま実務で使えます。要点は「情報を足す」ではなく「残すべき情報だけを残す」ことです。
- 知識記事を単一論点に分割する
長く多話題のナレッジ記事は、検索時に不要な断片まで持ち込みます。返金、停止、権限変更、見積修正のように単一論点へ切ると、必要なチャンクだけを入れやすくなります。 - アクション出力を絞る
CRMや基幹システムの全レスポンスをそのまま渡さず、次の推論に必要な項目だけ残します。顧客名、案件ID、次回予定、最新ステージのように、判断に使う最小限へ落とす発想です。 - 状態変数を会話履歴の外に持つ
顧客意図、ケース要約、account ID、直前アクション結果など、後から上書きされうる重要状態は明示的に保持します。会話履歴だけに頼ると、長会話で簡単に落ちます。 - guardrails を先に置く
API応答の必須項目が欠けていたら、そのまま推論させず止めます。想定外 escalation や誤更新は、モデル誤答より guardrail 不足で起きることが多くなります。 - 長会話専用の評価指標を持つ
PoCでは平均正答率だけで満足せず、5ターン超の解決率、聞き直し率、意図変更後の復元率、想定外 escalation 率を分けて追います。
この5点は、セマンティックレイヤー ともつながります。何を重要状態として持つかが曖昧だと、状態変数を作っても意味がありません。context rot 対策は、情報量の削減だけではなく、何が正本かを決める話でもあります。
PoCで確認すべき運用チェック項目
コンテキストロットは、公開デモや短い評価では見逃しやすいので、PoCの観測設計が重要です。最低でも次の4項目は別で見た方が、本番前に崩れを発見しやすくなります。
- 5ターン超の解決率:短会話の平均に埋もれやすい長会話の劣化を見る
- 聞き直し率:すでに答えた情報を再度要求していないかを見る
- 意図変更後の復元率:顧客が「やっぱり別案で」と変えた後に追従できるかを見る
- 想定外 escalation 率:API不備や文脈崩れで不要に人間へ倒れていないかを見る
ここまで見ると、単純な「成功/失敗」ではなく、どの場面で崩れるかが見えてきます。長会話でだけ落ちるなら context rot、最初から必要情報を引けないなら RAG不足、特定操作だけ失敗するなら権限不足、という切り分けがしやすくなります。
よくある質問
AIエージェントのコンテキストロットとは何ですか?
会話履歴、検索結果、ツール出力が同じコンテキスト枠を奪い合い、長い会話ほど以前の重要な前提が落ちて精度が崩れる現象です。モデルの賢さより、情報の入れ方で起きやすくなります。
RAG不足とコンテキストロットは同じですか?
同じではありません。RAG不足は必要知識を拾えていない状態で、コンテキストロットは拾った知識や履歴が多すぎて重要前提が押し出される状態です。
最初に効く対策は何ですか?
知識記事の分割、アクション出力の絞り込み、状態変数の明示保持が最も効きやすい対策です。モデル変更はその後でも遅くありません。
PoCで何を測れば本番事故を防げますか?
平均値だけでなく、5ターン超の解決率、聞き直し率、意図変更後の復元率、想定外 escalation 率を別で追うと判断しやすくなります。
関連ページと関連記事
コンテキストロットは、AIエージェントの失敗分析、権限設計、データ設計の中間にある論点です。関連ページもあわせて読むと、どこを直すべきか切り分けやすくなります。
- AIエージェント ガバナンスとは?権限、監査ログ、承認フローの設計を整理する:文脈崩れではなく統制面の前提を確認できます。
- AIエージェントのセマンティックレイヤーとは?CRM/SFAデータを誤読させない意味設計:何を重要状態として保持すべきかの前提を整理できます。
- AIエージェント基盤としてのSoAとは?権限・承認・監査ログの設計を整理する:会話外でどこに guardrail を置くかを考える補助になります。
- Agentforce 360とは?SalesforceがAI CRMへ進む理由とHeadless 360との関係:context rot がどのような製品文脈で語られているかを確認できます。
AIエージェントの運用崩れを減らしたい方へ
AIエージェントは、モデル選定より先に「何を残し、何を捨て、どこで人が止めるか」を決めると安定します。ファネルAiでは、営業・サポート・社内自動化の長会話フローを整理し、状態保持、guardrail、権限設計まで含めて実装方針を一緒に詰められます。
