生成AIトラブル事例7選|出典付きで見る情報漏えい・誤情報・著作権・炎上の典型パターン
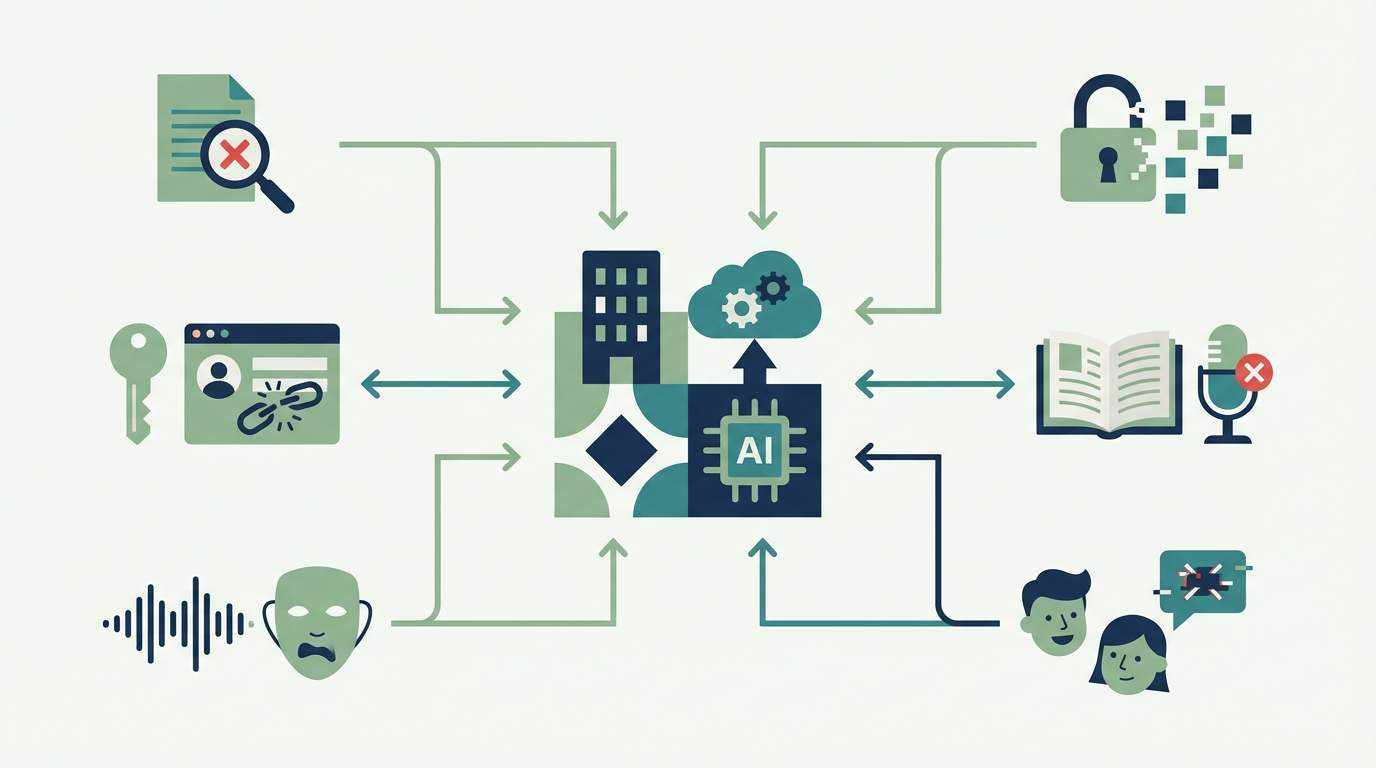
生成AIのトラブルを調べる人の多くは、単に「危ないらしい」と知りたいのではなく、社内ルールや承認フローをどこまで固めるべきかの判断材料を探しています。特にBtoB企業では、情報漏えい、誤情報、顧客向けチャットボットの誤案内、著作権、音声ディープフェイクのように、事故の型ごとに防ぎ方が変わります。
本記事では、外部ソースへのリンクを付けた7つの代表例を整理し、何が起きたのか、なぜ起きたのか、自社で何を先に整えるべきかまでつなげます。外部ソースはいずれも 2026年3月31日 時点でリンク確認していますが、進行中の訴訟や規制はその後に更新される可能性があります。
結論から言うと、生成AIトラブルは「AIが間違える」という一言では整理できません。入力データの持ち込み、ベンダー側の障害、正式文書への誤情報混入、顧客接点の誤案内、公開アウトプット、音声悪用、著作権訴訟のように起点ごとに分けて見ないと、必要な統制も見誤りやすくなります。
本記事のポイント
- 生成AIトラブルは1種類ではなく、情報漏えい、誤情報、顧客向け誤案内、著作権、音声ディープフェイクなど複数の型に分かれます。
- 事故はツール名だけで決まらず、入力データ、公開有無、顧客接点、権限設定、承認不在の組み合わせで起きやすくなります。
- 企業が先に整えるべきことは一律禁止ではなく、利用ルール、承認基準、リスク評価、監査ログを事故タイプごとに運用へ落とすことです。
この記事で扱うテーマ
関連キーワード
- 生成AI トラブル 事例
- 生成AI 情報漏えい 事例
- 生成AI 著作権 トラブル
- 生成AI ハルシネーション 事例
- 生成AI 失敗事例 企業
このページで答える質問
- 生成AIではどんなトラブルが起きる?
- 情報漏えいや誤情報の事故はどう起きる?
- 著作権や顧客向けチャットボットのリスクは何?
- 企業は何を先にルール化すべき?
生成AIトラブル事例の結論は「事故タイプごとに防止策を分けること」
同じ生成AIでも、社内メモの下書き、顧客向けチャットボット、営業電話AI、法務文書の作成補助では、事故の形がまったく違います。そのため、まずは AIリスクアセスメント で業務、データ、公開有無を分け、その上で 生成AI利用ルール と承認フローへ落とす方が実務に合います。
以下の7例は、企業が実際に遭遇しやすい失敗条件をまとめ直したものです。ニュースを並べるのではなく、事故の起点と再発防止策を見極める材料として使ってください。
| 類型 | 代表事例 | 起きたこと | 先に置くべき対策 | 出典 |
|---|---|---|---|---|
| 社内機密の持ち込み | Samsung関連報道 | 社員入力を起点に機密情報流出懸念が顕在化 | 入力禁止データ、許可済みツール、代替手段 | TechCrunch |
| ベンダー側のデータ露出 | OpenAI outage | 他人のチャットタイトルや一部課金情報が露出し得る状態 | ベンダー審査、最小投入、障害対応前提 | OpenAI |
| 誤情報の正式文書混入 | Mata v. Avianca | 架空判例を裁判資料へ提出し制裁 | 出典確認、公開前承認、証拠保全 | Justia |
| 顧客向け誤案内 | Air Canada chatbot | 誤案内に基づく返金対応で企業責任が争点化 | 回答範囲制限、公式情報同期、エスカレーション | The Guardian |
| 公開アウトプット炎上 | Gemini image issue | 不正確または不適切な画像生成で機能停止 | 公開前レビュー、用途制限、ブランド監修 | |
| 音声ディープフェイク | FCC ruling | AI音声利用が規制対象であることを明確化 | 同意取得、本人性表示、用途制限 | FCC |
| 著作権訴訟 | New York Times v. OpenAI | 学習利用と出力再現をめぐる紛争が訴訟化 | 利用規約確認、根拠保全、公開用途レビュー | Justia |
事例1: Samsung関連報道に見る社内機密の持ち込み事故
何が起きたか: 2023年5月2日、TechCrunch は、4月の内部データ漏えいを受けて Samsung が ChatGPT などの生成AIツール利用を一時制限したと報じました。記事内では、Samsung spokesperson が「安全に使える環境を整えるまで一時制限する」と説明しています。
なぜ起きたか: 生成AIの事故というとモデルの誤答に目が向きがちですが、実務で先に起きやすいのは、社員が外部サービスへ社内情報を持ち込む事故です。使う人に悪意がなくても、相談、要約、デバッグのつもりで貼り付けた内容が問題になります。
自社での示唆: ここで効くのは「使うな」と言うことより、何を入力禁止にするか、どのツールが許可済みか、使えない場合の代替手段をどう用意するかです。現場が勝手に持ち込みやすい背景は シャドーAI対策 の論点と重なります。
事例2: OpenAI障害に見るベンダー側のデータ露出
何が起きたか: OpenAI は 2023年3月24日、3月20日の ChatGPT 障害について、別ユーザーのチャット履歴タイトルが見える不具合があり、一部の有料ユーザーでは課金関連情報が露出し得る状態があったと公表しました。公式説明では、対象は特定の9時間帯にアクティブだった ChatGPT Plus ユーザーの 1.2% でした。
なぜ起きたか: これは社員の不注意ではなく、サービス提供側の不具合に起因する事故です。つまり、生成AIのリスクは「社員教育を徹底すれば終わり」ではなく、ベンダー側障害も前提にした設計が必要だと分かります。
自社での示唆: 機密情報をどこまで持ち込むかは、社員向けルールだけでなく、ベンダー審査、契約、ログ、障害時の運用方針まで含めて決める必要があります。最初の判断軸は AIリスクアセスメント に分けておくと扱いやすくなります。
出典: March 20 ChatGPT outage: Here’s what happened | OpenAI | 2023年3月24日
事例3: Mata v. Avianca に見る誤情報の正式文書混入
何が起きたか: 2023年6月22日、米連邦地裁の sanctions order では、ChatGPT が生成した架空判例を裁判資料へ提出し、その後も実在確認が不十分だったとして、弁護士らに制裁金などが命じられました。判決文では、AI利用自体が不適切なのではなく、提出物の正確性を担保する弁護士の gatekeeping role を放棄した点が問題視されています。
なぜ起きたか: 「それっぽい引用」が出る領域では、人が読んだだけでは誤りに気づきにくくなります。特に法務、契約、IR、広報のように外部提出や公開が前提の文書では、ハルシネーションはそのまま信用事故に直結します。
自社での示唆: 公式文書、対外説明、契約、提案書などは、AI利用可否よりも「どの時点で人が原典確認するか」を決める方が重要です。公開前の承認を曖昧にしないためには 生成AIの承認基準 を別で置いておくと運用しやすくなります。
出典: Mata v. Avianca, Inc., Document 54 | Justia | 2023年6月22日
事例4: Air Canada に見る顧客向けチャットボット誤案内
何が起きたか: 2024年2月16日、The Guardian は、Air Canada のチャットボットが葬儀割引運賃について誤った案内を行い、顧客がその案内を信じて購入した後の返金をめぐり、企業側が責任を負う判断が示されたと報じました。記事では、企業が「チャットボットは自分の行為に責任を持つ別個の存在だ」と主張した点も紹介されています。
なぜ起きたか: 顧客向け bot の失敗は、モデル性能より「どこまで答えさせるか」と「公式情報とどう同期するか」の設計ミスで起きやすくなります。FAQ から外れた問い合わせであっても、もっともらしい誤案内を返すだけで、企業責任の論点になります。
自社での示唆: 顧客接点で使う bot は、社内の下書きAIよりも強い統制が必要です。回答範囲を制限し、根拠が曖昧なときは人へ渡す設計にしないと事故率が上がります。ここは AIエージェントのガバナンス でいう「止める位置」の設計そのものです。
出典: Air Canada ordered to pay customer who was misled by airline’s chatbot | The Guardian | 2024年2月16日
事例5: Gemini画像生成問題に見る公開アウトプットの炎上
何が起きたか: Google は 2024年2月23日、Gemini の人物画像生成機能について、生成された画像の一部が inaccurate or even offensive だったとして、人物画像生成を一時停止すると公表しました。説明では、歴史的文脈や特定条件で本来広げるべきでない場面にまで tuning が効き、過剰補正が起きたとされています。
なぜ起きたか: 公開アウトプットの事故は、モデルの精度だけでなく、どの用途に出してよいかを決めずに本番運用へ載せたときに起きやすくなります。特に画像や広告表現は、事実性だけでなく、文脈、属性表現、ブランド毀損の観点でも炎上し得ます。
自社での示唆: 画像生成や対外発信でのAI利用は、下書き用途と本番公開を分けるべきです。広報、広告、採用、IR のような公開導線では、公開前レビューや用途制限を最初から前提にしてください。
出典: Gemini image generation got it wrong. We’ll do better. | Google | 2024年2月23日
事例6: FCC ruling に見るAI音声・ディープフェイクの規制対応
何が起きたか: 米 FCC は 2024年2月8日、AI が生成した human voices が Telephone Consumer Protection Act の artificial or prerecorded voice に含まれると明確化しました。ruling では、voice cloning が消費者保護上の新しい脅威になっていることや、同意なしの AI音声コールが規制対象であることが整理されています。
なぜ起きたか: 音声AIは、テキストAIより本人らしさや緊急性を演出しやすく、詐欺や誤認誘導に悪用されたときの被害が大きくなります。特に営業電話や顧客対応の自動化で本人確認や同意を曖昧にすると、コンプライアンス事故へ直結します。
自社での示唆: 音声AIを outbound で使うなら、同意取得、発信主体の明示、録音とログ、用途制限を最初からセットにすべきです。便利さの前に、規制対象のコミュニケーションであると理解しておく必要があります。
出典: FCC 24-17 Declaratory Ruling | FCC | Released 2024年2月8日
事例7: New York Times v. OpenAI に見る著作権訴訟リスク
何が起きたか: 2023年12月27日、The New York Times Company は OpenAI と Microsoft を相手に著作権侵害などを主張する訴訟を提起しました。OpenAI はその後、Times の主張に反論する説明ページを公開しています。これは 進行中の訴訟 であり、現時点で最終判断が確定したわけではありません。
なぜ起きたか: 生成AIの著作権リスクは、「AIが画像を作ったから危ない」という単純な話ではありません。学習利用、出力の再現性、引用と参照、商用利用、契約条件が重なり、争点が複層化しやすいのが特徴です。
自社での示唆: 企業が先にやるべきことは、公開物や納品物にAI生成物を使うときの審査基準を持つことです。特に画像、記事、ホワイトペーパー、提案書は、利用規約、元データ、編集履歴、根拠を残し、権利論点を曖昧にしないでください。
出典: The New York Times Company v. Microsoft Corporation et al | Justia docket | Complaint filed 2023年12月27日 / Reporting the facts about the New York Times’ lawsuit | OpenAI
企業が先に整えるべき4つの防止策
- 入力データの境界線を決める: 何を外部AIへ持ち込めないかを明文化し、匿名化や代替手段まで含めて示します。
- 公開前の承認ゲートを分ける: 社内下書き、顧客向け回答、公式公開物、音声発信で、必要なレビュー強度を分けます。
- 顧客接点と自動実行は別管理にする: FAQ bot、営業電話AI、更新系エージェントは、社内下書きAIより強い統制を前提に置きます。
- 事故後に説明できる記録を残す: 利用申請、承認、入力データ種別、出力用途、公開前レビュー、障害対応の記録を追える状態にします。
要するに、生成AI対策は「禁止」より先に、入力、公開、顧客接点、自動実行の4つを分けて運用することです。そこで必要になるのが、利用ルール、承認基準、ログ、責任分界の4点です。
よくある質問
この7事例をそのまま社内ルールへ転記してよいですか?
そのまま転記するより、自社の業務、データ、公開有無に引き直して使う方が安全です。ニュースの事実関係と、自社ルールの基準は分けて設計した方が実務に合います。
最初に整えるなら何から着手すべきですか?
最初は、入力禁止データと公開前レビューの承認ゲートです。この2つだけでも、情報漏えいと誤情報公開の大きな事故をかなり減らしやすくなります。
すべての生成AI利用を高リスク扱いすべきですか?
いいえ。社内下書き、顧客対応、公式公開、音声発信、自動実行ではリスクが違います。重要なのは一律禁止ではなく、用途ごとに必要な統制を変えることです。
事例記事はどのくらいの頻度で見直すべきですか?
少なくとも四半期ごと、または新ツール導入時、事故発生時、規制変更時に見直す方が良いです。特に訴訟や規制は日付とステータスを明示して更新してください。
関連ページと関連記事
事例を読むだけで終わらせず、社内ルールと承認フローへつなげるなら次のページが役に立ちます。
- AIリスクアセスメントの進め方:事故を、業務、データ、出力用途の組み合わせで評価する基準を整理できます。
- 生成AI利用ルールの作り方:入力禁止データ、例外運用、更新責任者まで含めて整えたい場合に向きます。
- 生成AIの承認基準とは?:承認、条件付き承認、差し戻しの線引きを曖昧にしたくない場合に役立ちます。
- シャドーAI対策とは?:禁止だけでは無断利用が減らない理由と、正規ルートの作り方を整理できます。
- AIエージェント ガバナンスとは?:顧客接点や更新系AIで、どこで人が止めるかを設計したい場合に確認してください。
生成AIの利用ルールと承認フローを整理したい場合
事例を見たうえで、自社ではどの事故を重く見るべきか、どこまで許可するべきかを決めたい場合は、公開相談窓口から現状を共有できます。
